
Fig. 1. Principle of Geodetector q-statistic ( Wang et al 2016)
(The bottom map, the color indicates the values of a population Y. The top map, the population Y is composed of L strata (h = 1, 2, ..., L), which are partitioned either by Y itself or by an explanatory variable X. The terms "stratification" and "partition" are equivalent, can be either classification or zonation. Between the two maps is the equation q(Y|X), in which the numerator is the summation of the within strata variance and the denominator is the pooled variance; N and s2 stand for the number of units and the variance of Y in a study area, respectively.)
[(N-L) q] / [(L-1)(1-q)] ~ F (L-1, N-L, g), where g is a non central parameter
Introduction
Spatially Stratified Heterogeneity (SSH) is a phenomena that the within strata are more similar than the between strata. Examples of this include landuse types and climate zones and remote sensing classiciation in spatial data, weeks and seasons and years in time series, occupations and age groups and incomes strata in more dimensions. SSH occurs in all scales from universe to DNA, and has been studied since Aristotle time.
Geodetector is a statistic to: (1) measure and identity SSH among data (Fig. 1); (2) test the coupling between two variables Y and X without assuming linearity of the association and with clear physical meanings (Fig. 1); and (3) investigate the general interaction between two explanatory variables X1 and X2 and a response variable Y, without any specific form of interaction such as the assumed product in econometrics (Fig. 2). Since it was published in 2010, Geodetector has been used by scholars from 62 countries in over 5,500 articles, many published in the top disciplinary or general journals, such as GRL, JGR, EST, RSE, JC, JH, WRR, and Lancet Planetory Health, Nature Communications.
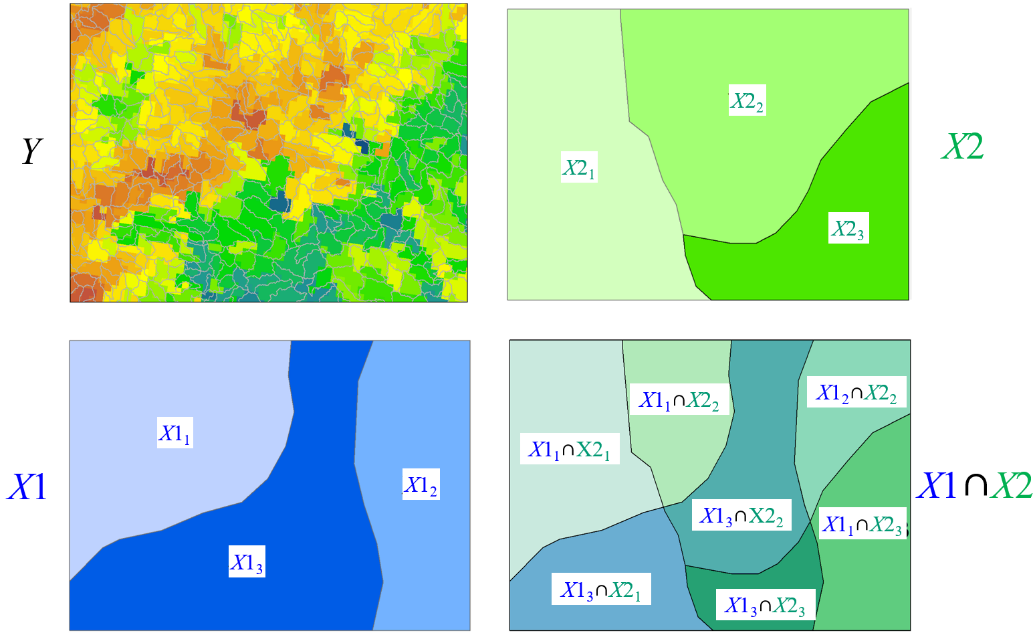
Fig. 2. The General interaction between explanatory variables X1 and X2 impacting on a response variable Y : q (Y | X1 ∩ X2)